SQL Server索引结构
索引是我们常见的优化数据库查询速度的重要手段和方式,本文将通过如下几个方面来描述SQL Server数据的索引结构相关知识。
- 什么是索引
对于索引的理解,我们可以看成一本书的目录,当书没有目录存在时候,要找到书上某一章的内容时非常麻烦,只有从第一页开始翻一页一页看,直到找到我们所要找的内容所在的那一页位置。
那么对于数据库也是如此,如果从表A中要找一个某一个字段B它的值等于C的所有的记录时候,在没有索引的情况下,数据库引擎只有一行行从表数据中遍历,在发现某一行数据中包含字段B的值为C时候讲这行数据放入结果集合中。当数据量小的时候没有什么,如果数据量大就会效率非常低,主要的消耗在于IO的读写。如同书的列子,建立索引可以解决这个问题。
那数据库系统是怎么建立索引的呢?其实就如同计算机科学的经典理论,其实索引的建立就是一个数据结构的问题。可以表简化成一纬的数组,查找一维数组中的某个值当如有顺序查找法(类似没有索引遍历)和诸如两分法或者就是更为经典的树的搜索。 数据库系统的索引的逻辑结构自然也是搜索树,常见的数据库系统是使用B树或者B+树B-树的方式来建立索引的。下面首先看下SQL Server 索引分类
- SQL Server 索引分类
1)聚合索引
聚集索引基于数据行的键值,在表内排序和存储这些数据行。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。
a.每个表只能有一个聚集索引;
b.表中的物理顺序和索引中行的物理顺序是相同的,创建任何非聚集索引之前要首先创建聚集索引,这是因为非聚集索引改变了表中行的物理顺序;
c.关键值的唯一性使用UNIQUE关键字或者由内部的唯一标识符明确维护。
d.在索引的创建过程中,SQL Server临时使用当前数据库的磁盘空间,所以要保证有足够的空间创建索引。
2)非聚合索引
非聚集索引具有完全独立于数据行的结构,使用非聚集索引不用将物理数据页中的数据按列排序,非聚集索引包含索引键值和指向表数据存储位置的行定位器。
3)全文索引
一种特殊类型的基于标记的功能索引,由SQL Server全文引擎生成和维护,用于帮助在字符串数据中搜索复杂的词,这种索引的结构与数据库引擎使用的聚集索引或非聚集索引的B树结构是不同的。类似于ElasticSearch的倒排索引。
4)XML索引
5)空间索引
6)筛选索引
7)列索引
后几种在新版本的SQL Server中才存在。本文的重点是聚合索引和非聚合索引。下面先看来看下关于索引的存储结构问题
- SQL Server基本数据存储结构
SQL Server的基本数据存错单位是页(Page)。页是数据库中的数据文件(.mdf 或 .ndf)分配的磁盘空间可以从逻辑上划分成页(从 0 到 n 连续编号)。 磁盘 I/O 操作在页级执行。 也就是说,SQL Server 读取或写入所有数据页。如同书本上每页的大小应该是一样的, 同样,SQL Server 所有数据页大小均相同 - 8 KB。关于页的相关知识会另外文章说明,
首先当SQL Server的某一张表不存在任何聚合索引时时,SQL Server会将页的数据按照堆的方式存储,可在存储为堆的表上创建一个或多个非聚集索引。 数据存储于堆中并且无需指定顺序。 通常,数据最初以行插入表时的顺序存储,但 数据库引擎 可能会在堆中四处移动数据,以便高效地存储行;因此,无法预测数据顺序。 如果需要从堆表中返回的行的顺序只有使用ORDER BY 语句。
下图是堆的常见结构:
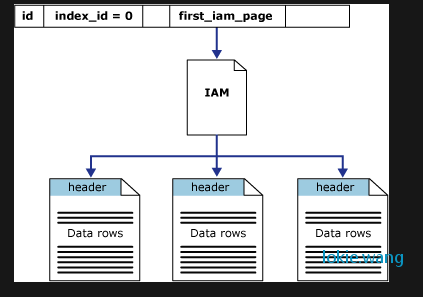
聚合索引:
- SQL Server 索引数据结构
本文为Lokie.Wang原创文章,转载无需和我联系,但请注明来自lokie博客http://lokie.wang
- 上一篇: Windwos下IIS访问NFS映射的盘
- 下一篇: Spring Boot注解大全

- 最新评论
- 总共0条评论


