GForce 920M Windows下CUDA和PyTorch的安装
有一台老笔记本基本配置为CPU: I7 3700M,集成显卡和GForce 920M,想用它发挥余热,学习一下GPU编程相关的内容,并想安装Pythorch进行一些基本的机器学习的学习。这里写下折腾的过程。
一. CUDA的安装
从NV官网中可以找到下面驱动和cuda的对应关系。
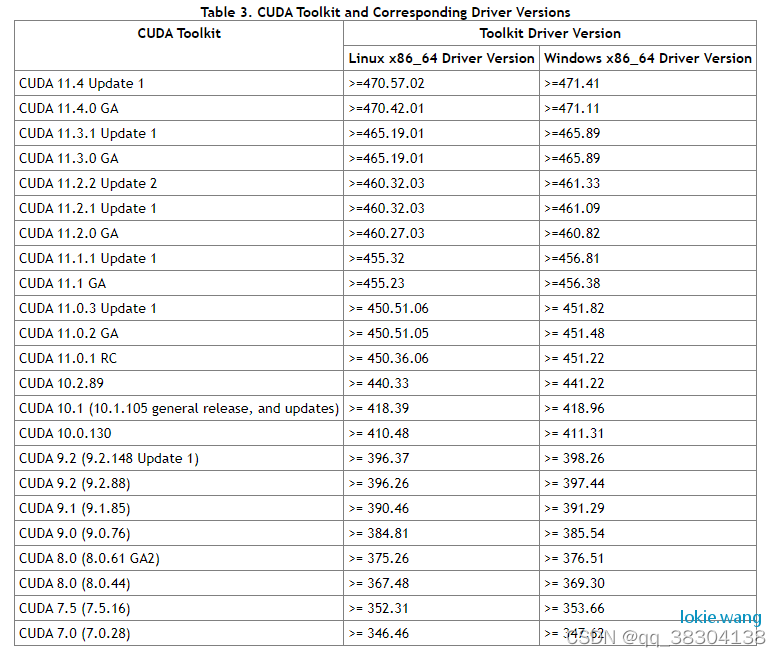
而929M这个显卡最高的驱动智能到42版本,因此可以知道,这款GPU最高可以安装到10.1版本的CUDA,安装方法是从官网下载CUDA 10.1的安装包进行安装,安装前可以先把NV显卡的驱动卸载掉。安装包可以从
https://developer.nvidia.com/cuda-10.1-download-archive-base
选择Windows ----> x86_64 ---> windows 10 ----> local 下载完整安装包,安装时选择自定义安装,将所有相关组件全部安装,这个包是包含了最新的驱动的。
安装完成后,可以通过如下方法测试:
- 打开CMD,输入nvcc -V测试CUDA是否安装成功
- 从CUDA安装目录运行官方自带的demo,C:Program FilesNVIDIA GPU Computing ToolkitCUDAv10.0extrasdemo_suite(如果自定义了安装路径需要修改该路径)
中的 bandwidthTest.exe 和 deviceQuery.exe 文件,如果最后都显示 Result = PASS 则说明安装成功
二. 安装cudnn
NVIDIA CUDA® 深度神经网络库 (cuDNN) 是一个 GPU 加速的深度神经网络基元库,能够以高度优化的方式实现标准例程(如前向和反向卷积、池化层、归一化和激活层)。 pytorch等深度学习框架都是用了cudnn。要安装cuddn需要注意cudnn和cuda版本之间的对应关系。cudnn的下载需要登录到nvida官方下载。特别注意需下载cuda对应的版本。下载得到的是一个zip包,解压后需要把相关文件复制到cuda的相关目录中去。主要是bin、include、lib三个文件。
三.安装pytorch
2.1 安装python
可以通过安装Anaconda 来安装conda,进而安装python 3.9.想conda的安装可以从https://docs.conda.io/projects/conda/en/stable/user-guide/install/index.html 中知道
安装完成后可以通过在命令行输入python命令获取版本号。
2.2 安装pytorch
由于需要支持在cuda 10.1上安装,需要下载旧的pytorch来安装。可以通过https://pytorch.org/get-started/previous-versions/ 来找到对应的版本,通过其中的命令来进行安装。通过在网页上搜索,正确的命令如下:
pip install torch==1.8.1+cu101 torchvision==0.9.1+cu101 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
1.8.1+cu101 代表版本1.8.1,并支持cuda 10.1.如果上述命令安装失败,可以直接访问
https://download.pytorch.org/whl/torch_stable.html 下载对应的包进行安装。搜索方式:
如:
cu101/torch-1.8.1%2Bcu101-cp38-cp38-win_amd64.whl
代表支援cuda 10.1,pytorch的版本是1.8.1,python的版本是3.9,系统是windows x64
验证
安装完毕后运行python 后执行如下命令:
import torch
torch.cuda.is_available()
>>> True
torch.cuda.current_device()
>>> 0
torch.cuda.device(0)
>>> <torch.cuda.device at 0x7efce0b03be0>
torch.cuda.device_count()
>>> 1
torch.cuda.get_device_name(0)
>>> 'GeForce 920M'
以上可以检验当前安装的pytorch的版本是否支持cuda和支持的cuda设备的数量和名称。
原以为以上就完成了pytorch和cuda的安装,可以用gpu进行一些基本的加速运算。事实上老旧GPU下没有那么简单。事实上在python执行如下代码会出错:
>>> torch.tensor([1.0, 2.0])
tensor([1., 2.])
>>> torch.tensor([1.0, 2.0]).cuda()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\balci\Anaconda3\envs\pytorch\lib\site-packages\torch\tensor.py", line 130, in __repr__
return torch._tensor_str._str(self)
File "C:\Users\balci\Anaconda3\envs\pytorch\lib\site-packages\torch\_tensor_str.py", line 311, in _str
tensor_str = _tensor_str(self, indent)
File "C:\Users\balci\Anaconda3\envs\pytorch\lib\site-packages\torch\_tensor_str.py", line 209, in _tensor_str
formatter = _Formatter(get_summarized_data(self) if summarize else self)
File "C:\Users\balci\Anaconda3\envs\pytorch\lib\site-packages\torch\_tensor_str.py", line 87, in __init__
nonzero_finite_vals = torch.masked_select(tensor_view, torch.isfinite(tensor_view) & tensor_view.ne(0))
File "C:\Users\balci\Anaconda3\envs\pytorch\lib\site-packages\torch\functional.py", line 227, in isfinite
return (tensor == tensor) & (tensor.abs() != inf)
RuntimeError: CUDA error: no kernel image is available for execution on the device
>>>
似乎是不支持某些算子,非常奇怪,明明pytorch官方给的包是支持的呀。进过一番调研,原来老旧GPU上没有那么简单,需要从源码编译pytorch才能完美支持。
3. 从源码安装pytorch
3.1 conda准备基本环境
conda create --prefix D:\condaEnv pip
conda activate D:\condaEnv
pip install --upgrade setuptools #Then upgrade setup tools.
conda install astunparse numpy ninja pyyaml mkl mkl-include setuptools cmake cffi typing_extensions future six requests dataclasses #安装其他支援包
3.2 安装vc 14.2
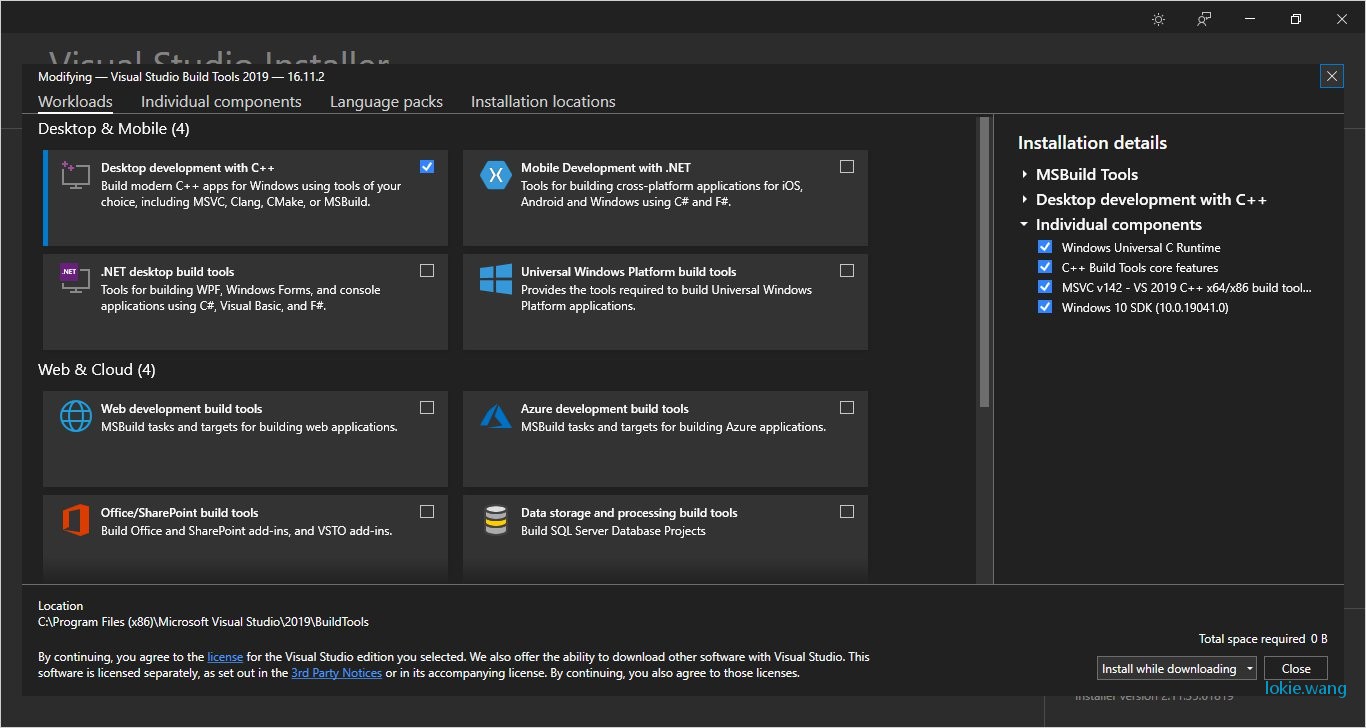
由于需要从源码编译,需要有c的编译器,这里可以直接安装vs 2019 社区版本,并安装c++的 workload,也可以单独安装vs 2019中的buid tool。 需要注意的是由于后面需要编译cuda的代码,而cuda之前已经安装过,在cuda安装的时候由于还有没安装vs2019,因此是cuda的vs2019插件是没有安装,因此在vs2019安装完成后,可以重新安装下cuda中组件。
3.3 安装Magma, mkl and sccache
Magma: 可以从https://s3.amazonaws.com/ossci-windows/magma_2.5.4_cuda101_release.7z. 下载到magma的release 包,下载完成后解开这个包,将响应的路径加入环境变量中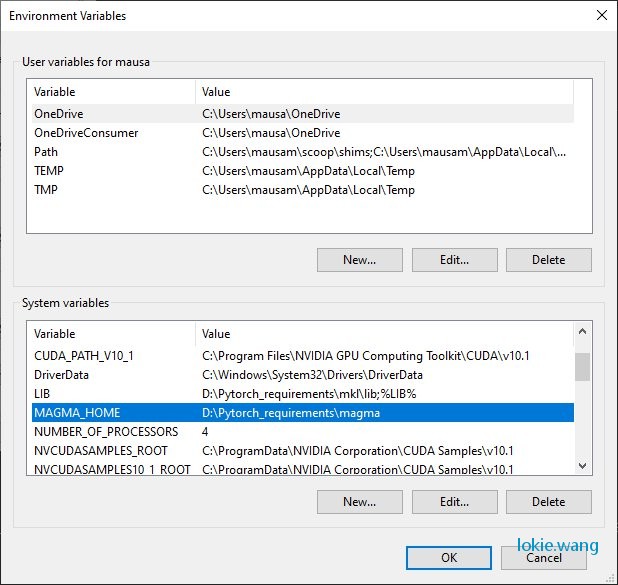
Mkl:可以从https://s3.amazonaws.com/ossci-windows/mkl_2020.2.254.7z 下载获取mkl的release包,解压放到目录中一样加入环境变量
set CMAKE_INCLUDE_PATH=D:\Pytorch_requirements\mkl\include
set LIB=D:\Pytorch_requirements\mkl\lib;%LIB%
sccache :
sccache is a ccache-like compiler caching tool. 非常好理解用于尽可能缓存编译的中间结果,避免反复的编译。windows 下可以通过
scoop install sccache
来安装,当然scoop是一个包管理器,可以通过如下方法安装。运行windows power shell。运行如下命令:
> Set-ExecutionPolicy RemoteSigned -Scope CurrentUser # Optional: Needed to run a remote script the first time
> irm get.scoop.sh | iex
3.4 设置GPU的算力
通过https://developer.nvidia.com/cuda-gpus 可以知道920M的算力是3.5,因此设置如下环境变量。
set TORCH_CUDA_ARCH_LIST=3.5
这一步非常重要,这个环境变量的设置才使得重新编译pytorch有意义,通过设置这个环境变量pytorch才可以支持老的GPU。
3.5 获取pytorch 的源码
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
git checkout v1.8.0
git submodule sync
git submodule update --init --recursive --jobs 1
3.6 开始编译pytorch
启动sccache
sccache --stop-server
sccache --start-server
编译:
python setup.py install --cmake
整个编译过程非常耗时,大约6.5小时左右,期间发生了一个错误:
ninja: build stopped: subcommand failed
查文档后需要设置如下环境变量:
set MAX_JOBS=1
重新执行:
python setup.py install --cmake
若干小时后可以完成编译。
3.7 测试
运行如下py代码
import torch
torch.cuda.is_available()
>>> True
torch.cuda.current_device()
>>> 0
torch.cuda.device(0)
>>> <torch.cuda.device at 0x7efce0b03be0>
torch.cuda.device_count()
>>> 1
torch.cuda.get_device_name(0)
>>> 'GeForce 920M'
t1 = torch.tensor([1, 2, 3]).cuda()
print(t1)
>>> tensor([1, 2, 3], device='cuda:0')由此原来的报错已经没有了,问题解决。
3.8 打包
由于每次需要重新编译,如果操作系统或者py重装又要经历一个漫长的过程,因此可以把之前的成果打包成WHL。这样只要如果重装python只要用pip install这个包就可以了,如果需要重装系统,也只需要重新安装cuda等。不需要在编译。执行如下命令:
python setup.py bdist_wheel
可以在pytorch下dist里找到这个这个包。
本文为Lokie.Wang原创文章,转载无需和我联系,但请注明来自lokie博客http://lokie.wang
- 上一篇: macOS 下L2TP的设置
- 下一篇: Windows服务器下的共享迁移Linux

- 最新评论
- 总共0条评论


